Let's consider an example of javaTpoint which focusses on the technical content. The following are the main goals:
- Improve the content: Display the content what the customers want to see in the future. In this way, content can be enhanced.
- Manage application efficiently: To keep track of all the activities in an application and storing the data in an existing database rather than storing the data in a new database.
- Faster: To improve the business faster but at a cheaper rate.
Achieving the above goals might be a difficult task as a huge amount of data is stored in different formats, so analyzing, storing and processing of data becomes very complex. The various tools are used to store different formats of data. The feasible solution for such a situation is to use the Data Pipeline. Data Pipeline integrates the data which is spread across different data sources, and it also processes the data on the same location.
What is a Data Pipeline?
AWS Data Pipeline is a web service that can access the data from different services and analyzes, processes the data at the same location, and then stores the data to different AWS services such as DynamoDB, Amazon S3, etc.
For example, using data pipeline, you can archive your web server logs to the Amazon S3 bucket on daily basis and then run the EMR cluster on these logs that generate the reports on the weekly basis.
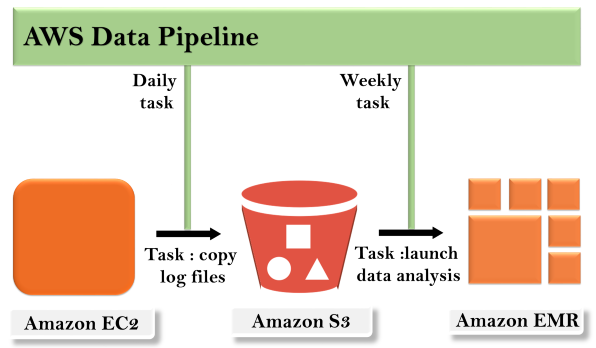
Concept of AWS Data Pipeline
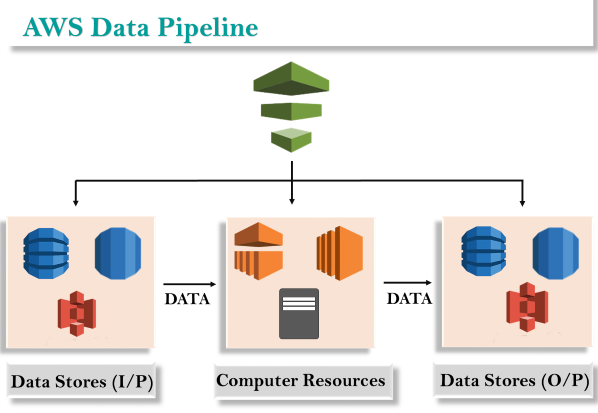
The concept of the AWS Data Pipeline is very simple. We have a Data Pipeline sitting on the top. We have input stores which could be Amazon S3, Dynamo DB or Redshift. Data from these input stores are sent to the Data Pipeline. Data Pipeline analyzes, processes the data and then the results are sent to the output stores. These output stores could be an Amazon Redshift, Amazon S3 or Redshift.
Advantages of AWS Data Pipeline
- Easy to use
AWS Data Pipeline is very simple to create as AWS provides a drag and drop console, i.e., you do not have to write the business logic to create a data pipeline. - Distributed
It is built on Distributed and reliable infrastructure. If any fault occurs in activity when creating a Data Pipeline, then AWS Data Pipeline service will retry the activity. - Flexible
Data Pipeline also supports various features such as scheduling, dependency tracking, and error handling. Data Pipeline can perform various actions such as run Amazon EMR jobs, execute the SQL Queries against the databases, or execute the custom applications running on the EC2 instances. - Inexpensive
AWS Data Pipeline is very inexpensive to use, and it is built at a low monthly rate. - Scalabl
By using the Data Pipeline, you can dispatch the work to one or many machines serially as well as parallelly. - Transparent
AWS Data Pipeline offers full control over the computational resources such as EC2 instances or EMR reports.
Components of AWS Data Pipeline
Following are the main components of the AWS Data Pipeline:
- Pipeline Definition
It specifies how business logic should communicate with the Data Pipeline. It contains different information:- Data Nodes
It specifies the name, location, and format of the data sources such as Amazon S3, Dynamo DB, etc. - Activities
Activities are the actions that perform the SQL Queries on the databases, transforms the data from one data source to another data source. - Schedules
Scheduling is performed on the Activities. - Preconditions
Preconditions must be satisfied before scheduling the activities. For example, you want to move the data from Amazon S3, then precondition is to check whether the data is available in Amazon S3 or not. If the precondition is satisfied, then the activity will be performed. - Resources
You have compute resources such as Amazon EC2 or EMR cluster. - Actions
It updates the status about your pipeline such as by sending an email to you or trigger an alarm.
- Data Nodes
- Pipeline
It consists of three important items:- Pipeline components
We have already discussed about the pipeline components. It basically how you communicate your Data Pipeline to the AWS services. - Instances
When all the pipeline components are compiled in a pipeline, then it creates an actionable instance which contains the information of a specific task. - Attempts
We know that Data Pipeline allows you to retry the failed operations. These are nothing but Attempts.
- Pipeline components
- Task Runner
Task Runner is an application that polls the tasks from the Data Pipeline and performs the tasks.
Architecture of Task Runner
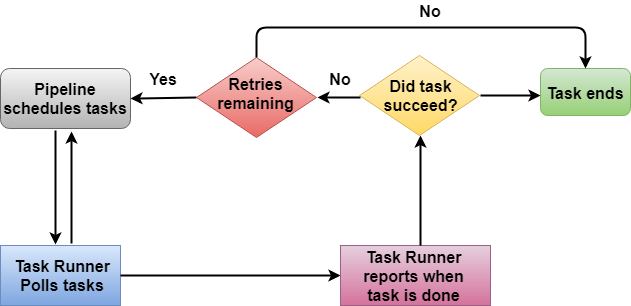
In the above architecture, Task Runner polls the tasks from the Data Pipeline. Task Runner reports its progress as soon as the task is done. After reporting, the condition is checked whether the task has been succeeded or not. If a task is succeeded, then the task ends and if no, retry attempts are checked. If retry attempts are remaining, then the whole process continues again; otherwise, the task is ended abruptly.
Creating a Data Pipeline
- Sign in to the AWS Management Console.
- First, we will create the Dynamo DB table and two S3 buckets.
- Now, we will create the Dynamo DB table. Click on the create table.
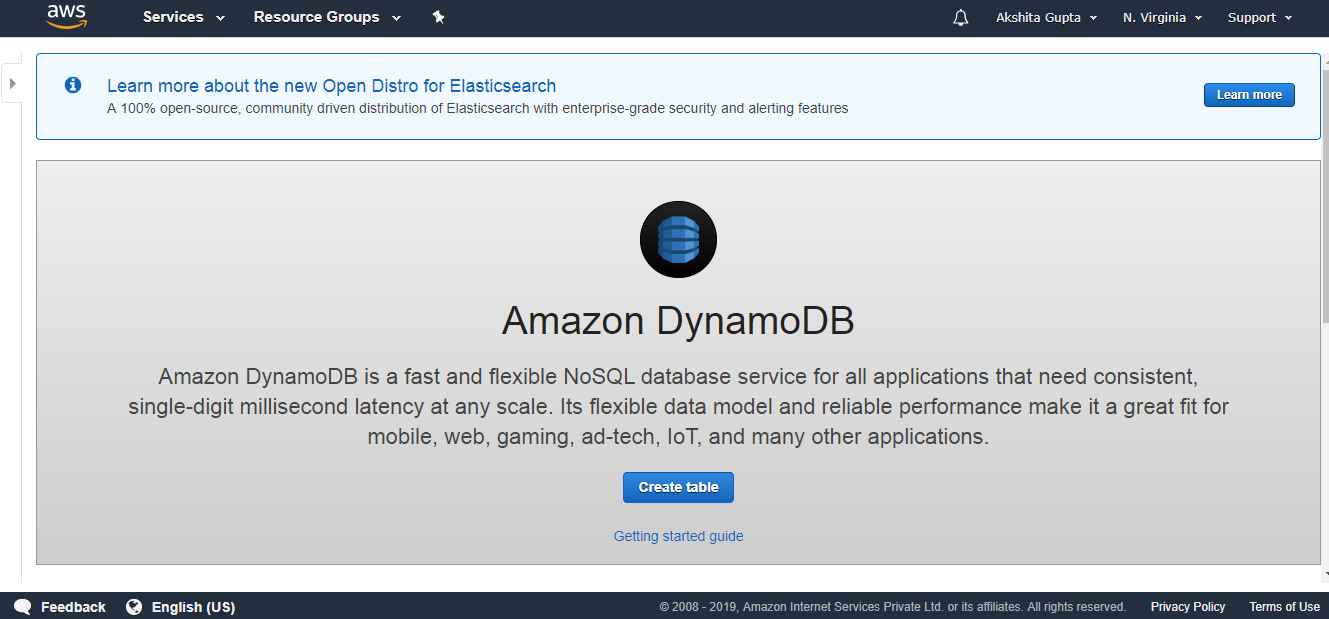
- Fill the following details such as table name, Primary key to create a new table.
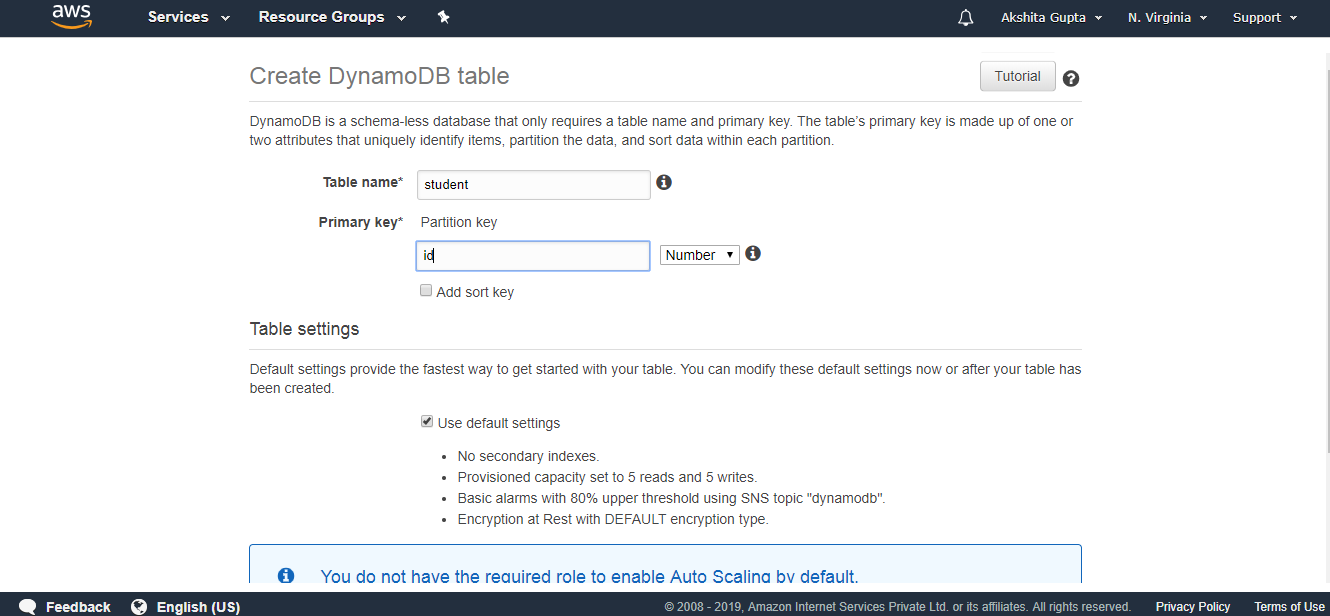
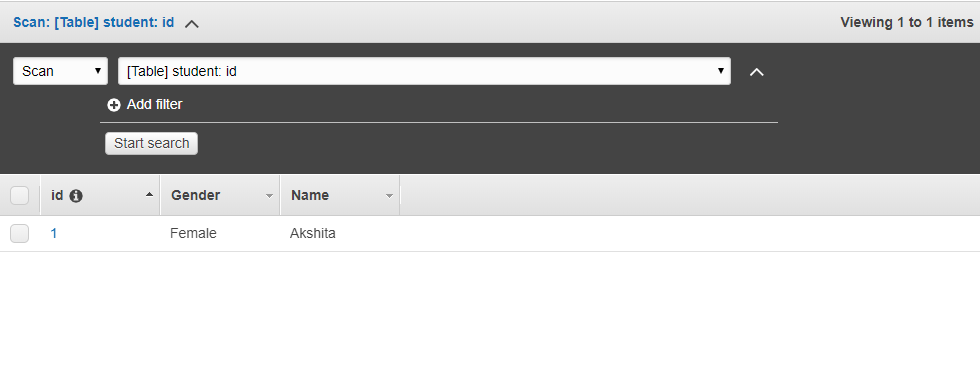
- The below screen shows that the table "student" has been created.
- Click on the items and then click on create an item.
- We add three items, i.e., id, Name, and Gender.
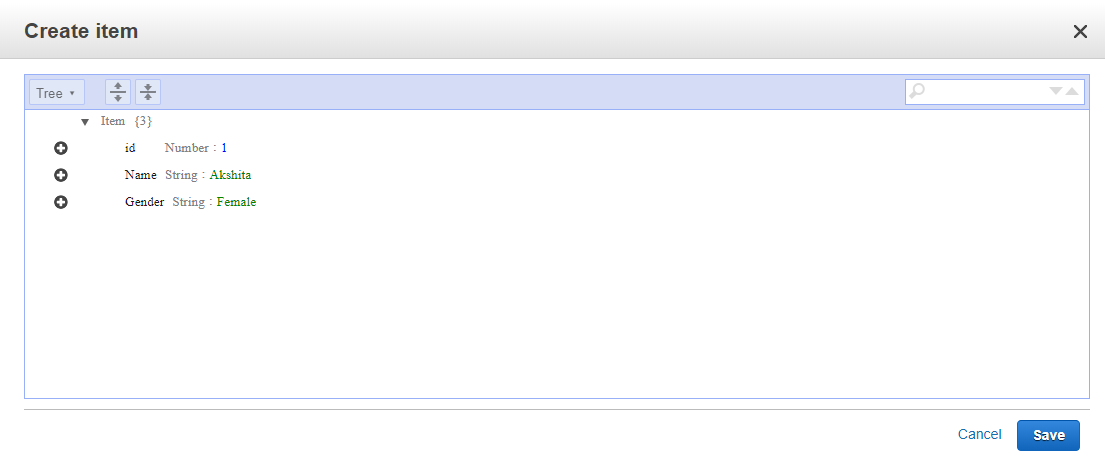
- The below screen shows that data is inserted in a DynamoDB table.
- Now we create two S3 buckets. First will store the data that we are exporting from the DynamoDB and second will store the logs.
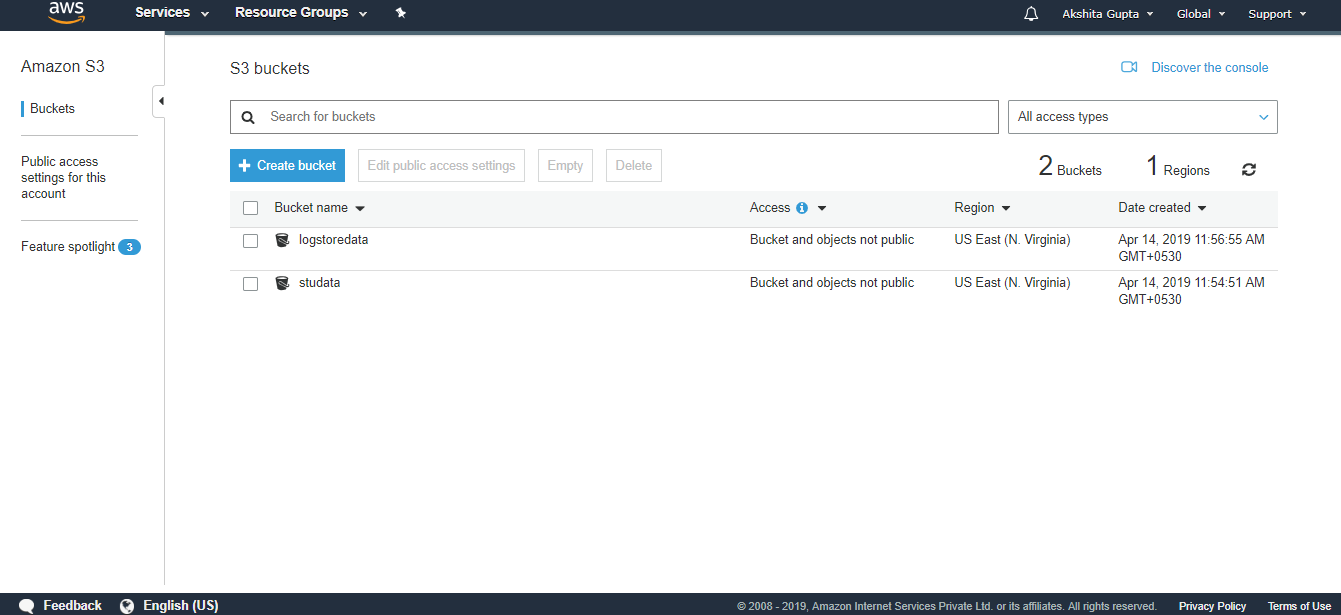
We have created two buckets, i.e., logstoredata and studata. The logstoredata bucket stores the logs while studata bucket stores the data that we are exporting from the DynamoDB.
- Now we create the Data Pipeline. Move to the data Pipeline service and then click on the Get started button

- Fill the following details to create a pipeline, and then click on the Edit on Architect if you want to change any component in a pipeline.
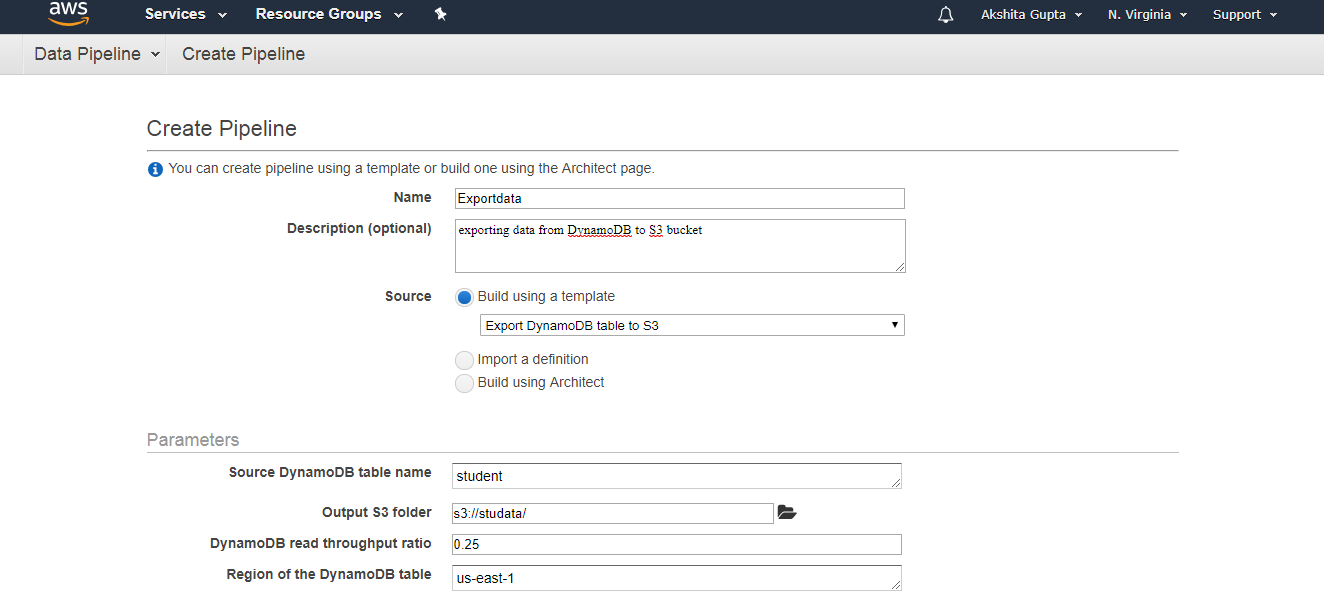
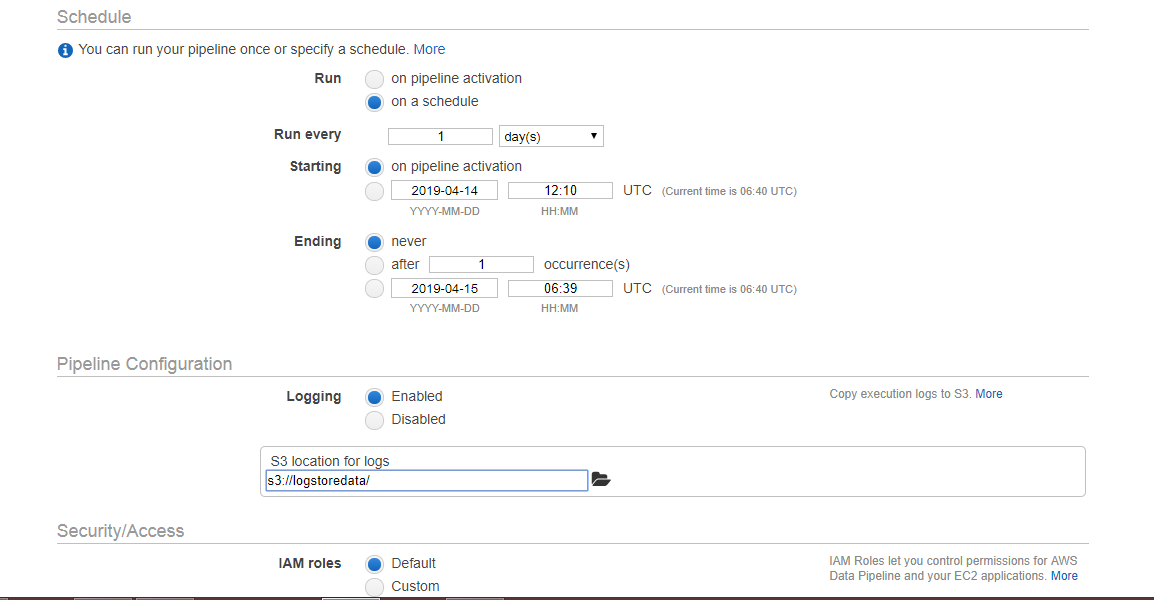
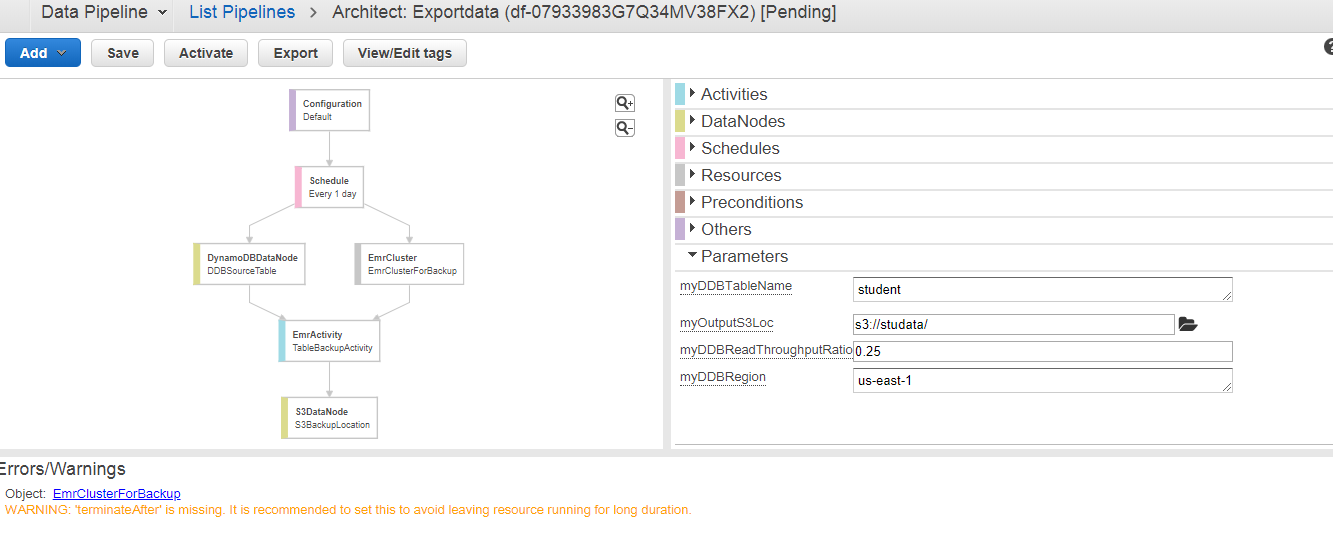
- The below screen appears on clicking on the Edit in Architect. We can see that the warning occurs, i.e., TerminateAfter is missing. To remove this warning, you need to add the new field of TerminateAfter in Resources. After adding the field, click on the Activate Button.
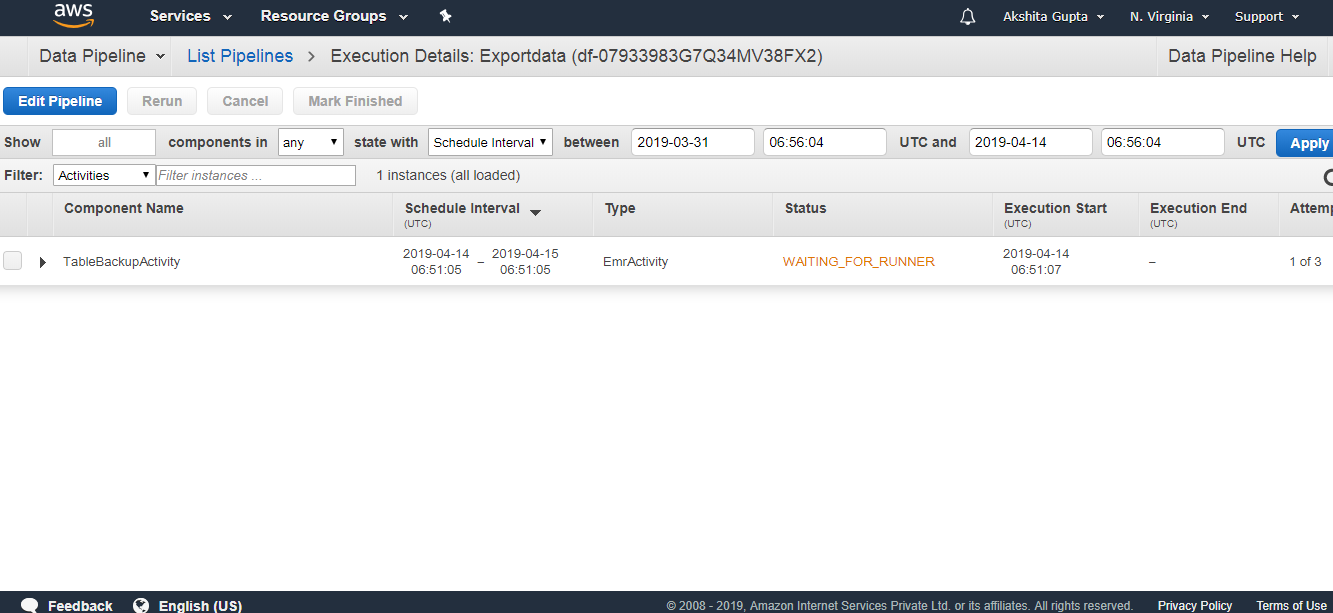
- Initially, WAITING_FOR_DEPENDENCIES status appears. On refreshing, status is WAITING_FOR_RUNNER. As soon as the Running state appears, you can check your S3 bucket, the data will be stored there.

No comments:
Post a Comment