- NonRelational Database is a database that does not follow the relational database model provided by the relational database management system.
- It is a NoSQL database, we have seen a steady growth in Non Relational Database with the rise in Big data applications.
- We have a NonRelational Database. Inside the database, we have a collection. Inside a collection, we have got a document, and inside the document, we have key-value pairs. If we talk in a relational sense then Collection is a table, the document is a row, and row consists of key-value pairs.
How does a Non Relational database work?
A Non Relational database model uses a variety of different data models such as key-value, document, Graph, in-memory, and search.
Let's understand through an example.
- In a relational database, a book record consists of separate tables, and the relationship between tables are defined by primary and foreign constraints. For example, Book table has three columns, i.e., Book id, Book title and Edition Number, Author table has three columns, i.e., Author id, Author name, and Book id. The relationship model is designed so that the database can enforce referential integrity between the tables to reduce redundancy.
- In NonRelational database, records are stored in the form of json format. Each book item such as Book id, Book title, Edition Number, Author id, Author name is stored as attributes in a document.
Why to use Non Relational database
Non Relational database is used because of the following features:
- Flexibility: It has a very flexible data model which provides faster and iterative development. The flexible model of Non Relational database makes an ideal for structured, semi-structured and unstructured data.
- Scalability: Non Relational databases provide scaling out by using distributed clusters of hardware rather than scaling up by adding expensive servers.
- High-performance: Non Relational databases use some specific data models such as key-value, document, etc that provides higher performance than relational databases.
- Highly functional: Non Relational databases provide highly functional APIs and data types for their respective data models.
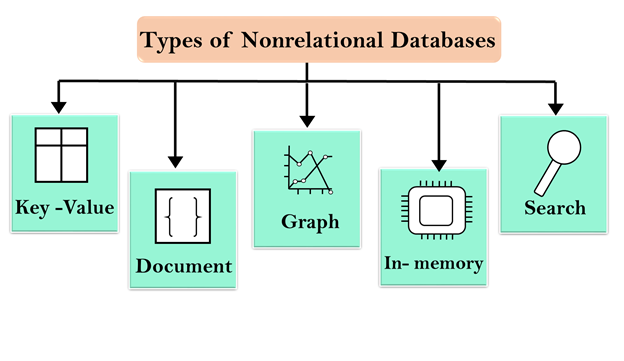
Non Relational database types
- Key value
- Document
- Graph
- In-memory
- Search
Key value
- A Key-value database is a nonrelational database which stores the data in the form of key value.
- Key-value databases provide highly partitionable and horizontal scaling that other types of databases cannot achieve.
- Key-value databases are used by those enterprises who want to store large volumes of data without any performance overhead.
- A key in the key-value pair must be unique, and it allows you to access the value associated with the key.
- Redis, Riak, and Oracle NoSQL are examples of key-value databases.
- A key-value store is a Big-Hash table of keys and values.
- A key is auto-generated while the value can be a string, JSON, BLOB, etc.
- A key value has a hash table which consists of a key and a pointer pointing to a particular data.
- A hash table is a bucket which consists of a logical group of keys.
Consider the simple example in which key is a student id and the value associated with the key is the name of the student.
| Key | Value |
|---|---|
| 1 | Akshita |
| 2 | Ankita |
| 3 | Yesha |
Disadvantages of Key-Value database:
- It does not provide the capabilities that traditional database system provides such as consistency when multiple transactions are executed simultaneously. Such capabilities are provided by the application itself.
- When the volume of data increases, then maintaining a unique key becomes a difficult task.
Document
- The document database is a nonrelational database used to store the semistructured data as documents.
- The document database is required for developers as data in the application tier is represented as JSON format.
- In a Document database, a document can have the same or a different data structure.
- Documents are grouped into collections which behave similarly as a table in the relational database.
- The document database is very popular as it allows you to persist the data in a database by using the same model that you use in your application code.
- Apache CouchDB, MongoDB are examples of a Document database.
Graph
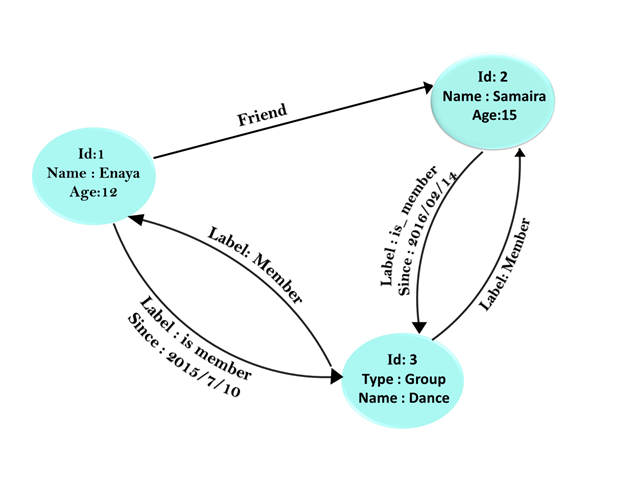
- A Graph database is a network database represented by edges and nodes to store the data.
- A Graph can be easily transformed from one model to another model by using a Graph database.
- Nodes have some relationships, which is represented by edges between the nodes.
- Some defined properties are associated with both nodes and edges.
- The Graph contains nodes and edges. Nodes are used to store the entities while edges are used to store the relationship between edges.
- An edge has a start node, end node, type, and direction. It also describes the parent-child relationship.
- Traversing the joins in a Graph database is very fast because the relationship between the nodes is not calculated at query time but it is persisted in a database.
In-memory
- An in-memory database is a type of nonrelational database that depends on memory for data storage rather than storing the data on disk or SSDs.
- It minimizes the response time by eliminating the need to access disks.
- Since the data is stored and managed in main memory, therefore it is at risk of data lost on server failure.
- An In-memory database is ideal for applications that require microsecond response time.
- The use cases of In-memory database are Real-time bidding, Gaming Leaderboards, and caching.
Search
- Search database is a nonrelational database which is used to search the data content.
- It uses indexes to categorize the similar characteristics among the data, and facilitate the search capability.
- It is mainly used with data that may be long, semistructured or unstructured data.
- It offers some specialized methods such as full-text search, complex search expressions, and ranking of search results.

No comments:
Post a Comment